1 背景
(1)在记忆网络中,主要由4个模块组成:I、G、O、R,前面也提到I和G模块其实并没有进行多复杂的操作,只是将原始文本进行向量表示后直接存储在记忆槽中。而主要工作集中在O和R模块,O用来选择与问题相关的记忆,R用来回答,而这两部分都需要监督,也就是需要知道O模块中选择的记忆是否正确,R生成的答案是否正确,这种模型多处需要监督,而且不太容易使用常见的BP算法进行训练,这就限制了模型的推广。
(2)而这篇论文就是在前一篇Memory networks的基础上提出来的,针对其中出现的问题,采用了端到端的模型结构(End-to-End),因此模型需要的监督更少,能够更好的训练模型。
2 具体内容
论文中提出了单层和多层两种结构,多层就是将单层网络进行堆叠起来的。
(1)单层结构
如图所示,模型主要包含了A、B、C、W四个矩阵,其中,B是用来对问题进行向量编码,W是最终输出的权重矩阵,而A和C都是将输入的文本编码成词向量,然后分别存入Input和Output模块,这两个模块的值是对应的。
其具体内容如下:
输入模块:输入模块主要是对文本进行编码,这里采用了文章表示法模型二的思想(具体见张俊林博士关于深度学习解决机器阅读理解任务研究进展的相关介绍),用一个向量来表示句子的整体语义信息(根据一句话中各单词的词向量,将其压缩成一个句向量)。论文中提出了两种编码方式,bow和位置编码。bow就是直接将一个句子中所有单词的词向量求和表示成一个向量的形式(表示法模型2中权重系数为1的情况),这种表示方法最明显的缺点就是不能捕获一句话中单词之间的位置信息。对于位置编码的方法,给不同位置的单词设置不同的权重(即模型二中的权重系数是由该单词所在位置决定的,而不全部是1),然后对各个单词的词向量按照不同的权重加权求和得到句子的整体表示,位置编码方法的公式如下: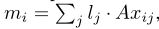
此外为了引入时序信息,在上面mi的基础上又加上了每句话出现顺序的矩阵,所以最后每句话对应的记忆mi的表达式如下: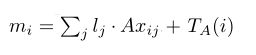
记忆模块:主要由两部分组成,input和output模块,统称为记忆槽,矩阵A和C都是将输入的文本编码成词向量,然后分别存入Input和Output模块。
输出模块:输入的文本信息通过编码成向量保存在记忆槽(input和outpu)中,input用来和question编码得到的向量相乘得到每句话和问题的相关性(这里可以看成是注意力权重),output模块则是通过相关性进行加权求和得到输出向量o。
- step1:将问题经过输入模块编码成一个向量u,然后将其与每个mi点积得到两个向量之间的相似度,再通过一个softmax函数进行归一化处理:
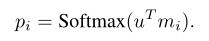
- step2:通过上述的相关性指标,对output中的各个记忆ci按照pi进行加权求和得到模型的输出向量o,公式如下:
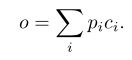
Response模块:该模块主要根据输入信息产生最终的答案,具体是其结合o和q两个向量的和与W相乘再经过一个softmax函数产生各个单词是答案的概率,使用交叉熵损失函数作为目标函数进行训练。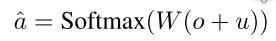
(2)多层结构
多层结构其实就是将多个单层模型堆叠起来,其结构图如下: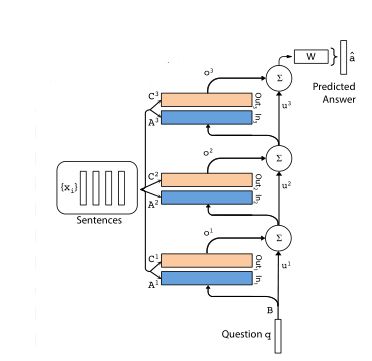
整体来说还是比较好理解的,上面几层的问题输入就是下层o与u的和,公式为: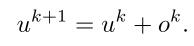
至于对文本语义表示中的矩阵Ai和Ci,为了减少参数量,论文中提出了两种方法:
- Adjacent:这种方法让相邻层之间的A=C。也就是说Ak+1=Ck,此外W等于顶层的C,B等于底层的A,这样就减少了一半的参数量。
- Layer-wise(RNN-like):与RNN相似,采用完全共享参数的方法,即各层之间参数均相等。Ak=…=A2=A1,Ck=…=C2=C1。由于这样会大大的减少参数量导致模型效果变差,所以提出一种改进方法,即令uk+1=Huk+ok,也就是在每一层之间加一个线性映射矩阵H。
对于最后的输出,其计算公式如下: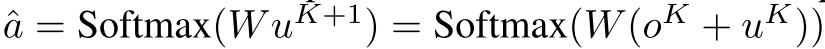
3 小结
(1)看了最开始的Memory network那篇论文,虽然还是能够看懂,但是至于怎么将其很好的用起来,还是很模糊,于是这篇端到端的记忆网络就提供了很好的使用范例,论文中也设计了两个实验任务(问答和语言模型),看了实验代码清楚多了。
(2)其实在这个结构上还是有很多改进的地方,当初看这篇论文的时候也想到一些,比如在记忆模块引入混沌概念,动态表示记忆。后面才发现这一系列的最后一篇论文中就是动态记忆-_-||